Visual content must be labeled to facilitate navigation and retrieval, or provide ground truth data for supervised machine learning approaches. The efficiency of labeling techniques is crucial to produce numerous qualitative labels, but existing techniques remain sparsely evaluated. We systematically evaluate the efficiency of tagging and browsing tasks in relation to the number of images displayed, interaction modes, and the image visual complexity. Tagging consists in focusing on a single image to assign multiple labels (image-oriented strategy), and browsing in focusing on a single label to assign to multiple images (label-oriented strategy). In a first experiment, we focus on the nudges inducing participants to adopt one of the strategies (n=18). In a second experiment, we evaluate the efficiency of the strategies (n=24). Results suggest an image-oriented strategy (tagging task) leads to shorter annotation times, especially for complex images, and participants tend to adopt it regardless of the conditions they face.
2023
Interaction TechniqueEmpirical StudyImage Labeling
See also PvD Squish this Model-based Evaluation of RBIT
Labeling Images using Tagging and Browsing Tasks Labeling an image is usually performed via two stereotypical tasks: tagging consists in assigning multiple labels to a single image, while browsing consists in focusing on a single label to assign to multiple images (see the right-hand figure or at [00:19] in the video figure). Selecting pre-suggested tags when adding a photo on Flickr is an example of the former, whereas image-based CAPTCHAs are a common example of the latter. While the task characteristics might greatly influence the annotator performance when labeling images, i.e., the time to produce the tags and their quality, their efficiency remains sparsely evaluated.

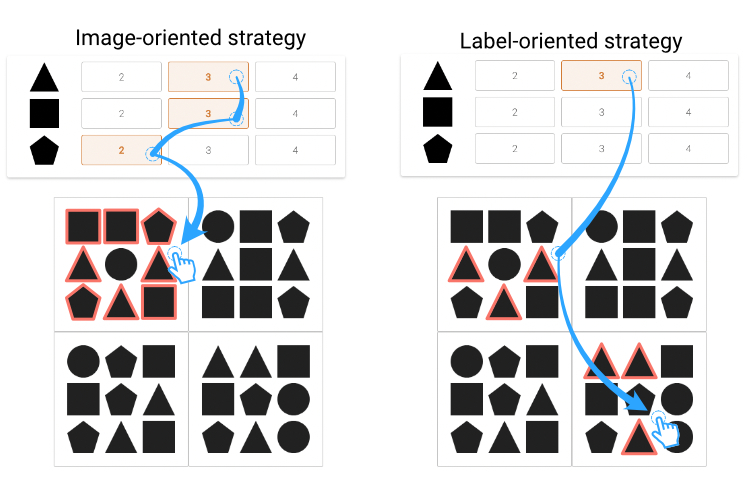
Underlying Strategies to Tagging and Browsing The literature on image labeling tools does not provide a rigorous definition of tagging and browsing tasks. The lack of a definition makes it challenging to identify their design implications, the interactions they should support, and their impact on user performance. For instance, if an annotator faces a set of images and tags each of them sequentially with all possible labels, are they performing a tagging or a browsing task? To systematically study these tasks and all possible variants, we rather study their underlying strategies, i.e., tagging single images sequentially (image-oriented) and tagging a single label on all images (label-oriented). The image below presents both strategies with an abstract task in which annotators must count shapes in images composed of 9 of them, and indicate the number of shapes using labels.
Designing an Abstract Task Building a set of natural images that provide distinct visual complexity levels and represent concepts that any annotator can relate to is a challenging task. To fully control these variables, we rather simulate an image labeling task using abstract images. These images consist of circles and polygons that represent features of a natural image, such as the type, number, and size of objects present in a scene. We vary the image visual complexity by manipulating the set of shapes and define three distinct levels (see right-hand figure). The low level differentiates shapes by colors, a known pop-out feature. The medium level consists of polygons with 3 to 5 sides. The high level consists of polygons with 8 to 10 sides that lack salient features.

User Study: Studying the User Preference and Performance for Labeling Strategies In a first experiment, we investigated the effects of the image visual complexity, the number of images displayed, and the persistence of labels on the user performance and the adoption of strategies. It followed a within-subject design involving 18 participants. We list two important findings from this experiment. Half of the participants used an image-oriented strategy throughout the entire experiment, a behavior which did not seem to be affected by the experimental factors. This suggests that following a tagging task was preferred overall. Our results also hint that persistent buttons nudge participants into adopting a label-oriented strategy. A second experiment compared how the two strategies may impact user performance. In this regard, we fix the strategy and force participants to use one or the other. The major finding of this second experiment is that an image-oriented strategy seems to produce shorter labeling times overall, particularly when labeling images with a high visual complexity. Experimental results indicate that completing a block of 9 images using an image-oriented strategy took in average 21.99s [2.03, 42.97] less than using a label-oriented strategy, which can have a great impact on the long-term for large image sets. Combined with results from the first experiment, this suggests tagging tasks provide advantages over browsing tasks in specific contexts.
Design Recommendations The results of the first experiment suggest that an image-oriented strategy is more likely to be adopted by default, and the results of the second experiment showed evidence of shorter labeling times using this strategy compared to a label-oriented strategy. We also found evidence that the label persistence nudge annotators into using a label-oriented strategy, and that overall they tended to find this strategy as being efficient more often than the image-oriented strategy. These findings underline two pieces of information: tagging tasks seem to provide advantages over browsing tasks overall, and they highlight a trade-off in the efficiency of browsing tasks and the perception annotators have of them. Designers should therefore: 1) prioritize tagging tasks to maximize the annotator labeling performance, 2) consider the image visual complexity when designing a labeling tool, 3) mind mode errors.
User Preference and Performance using Tagging and Browsing for Image Labeling Bruno Fruchard, Sylvain Malacria, Géry Casiez, Stéphane Huot CHI'23: Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems